
简介
理解并发和并行
- 并行对应的是多进程
- 并发对应的是协程、线程(异步编程)
协程
协程之在python2中的yield使用
在python2中由于没有原生的协程,只有基于生成器的协程(yield),生成器可以通过yield暂停执行和返回数据,也支持send向生成器发送数据,通过next方法取值,使用send方式需要注意:在一个生成器函数未启动之前,是不能传递数值进去。必须先传递一个None进去或者调用一次next()方法,才能进行传值操作。
In [86]: def test(x):
...: y = "say:"+x
...: yield x
...: yield y
...:
In [87]: g = test("zhangsan")
In [88]: next(g) # 取的是x值
Out[88]: 'zhangsan'
In [89]: next(g) # 取的是y的值
Out[89]: 'say:zhangsan'
In [90]: next(g) # 没有值取了,所以会抛出异常
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-90-e734f8aca5ac> in <module>
----> 1 next(g)
StopIteration:
使用send方法
In [124]: def test(x):
...: y = "say:"+x
...: yield x
...: yield y
...:
In [125]: g = test("doge")
In [126]: g.send("pig") # 会报错,生成器还没有启动,必须send(None)或者调用next方法先
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-126-f07b448372e3> in <module>
----> 1 g.send("pig")
TypeError: can't send non-None value to a just-started generator
In [127]: next(g)
Out[127]: 'doge' # 获取yield x 的值
In [128]: g.send("pig")
Out[128]: 'say:doge' # 获取 yield y 的值
In [129]: next(g) # 没有yiled 的值了,是不是好奇send “pig” 没有反应呢?因为要接受send的值必须是 = yield x 这个格式,在等号的右边yield
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-129-e734f8aca5ac> in <module>
----> 1 next(g)
StopIteration:下面实例:接受send的值,注意是z = yield x
In [139]: def test(x):
...: y = "say:"+x
...: z = yield x
...: yield z
...: yield y
...:
In [140]: g2 = test("doge")
In [141]: next(g2) # 启动生成器,输出的是yield x的值
Out[141]: 'doge'
In [142]: g2.send("pig") # 启动生成器,输出的是yield z的值
Out[142]: 'pig'
In [143]: next(g2)
Out[143]: 'say:doge' # 启动生成器,输出的是yield y的值需要注意的是,在python2中yield只是起到异步的作用,在效率上并没有得到提升,只是起到了协程的上下文切换。在python2中如果需要协程,可以用gevent库,到python3.3又新增了yield from,区别在yield from可以传递一个迭代器,python3.6之后新增asyncio真正的原生协程
协程之python2中gevent
在python2协程的主流实现方法是使用gevent模块。需要单独pip install gevent,由于协程对于操作系统是无感知的,其操作是开发人员自己去完成的。
import time
import threading
import gevent
import requests
from gevent.pool import Pool
from lxml import etree
def request_web():
url = "https://wsppx.cn/date/2021/06/"
resp = requests.get(url)
text = resp.text
html = etree.HTML(text)
wsppx_urls = html.xpath("//h2[@class='item-title']/a/@href")
return wsppx_urls
def request_artice(url):
resp = requests.get(url)
text = resp.text
html = etree.HTML(text)
wsppx_title = html.xpath("//h1[@class='entry-title']/text()")
info = html.xpath("//div[@class='entry-info']/a/text()")
print('current thread %s .' % threading.current_thread().name)
print(url, wsppx_title, info)
def run():
urls = request_web()
jobs = []
for url in urls:
jobs.append(gevent.spawn(request_artice, url))
gevent.joinall(jobs)
for job in jobs:
job.run()
# p = Pool(20)
# for url in urls:
# p.apply_async(request_artice,args=(url,))
# p.join()
def wait(x):
print("wait sleep {}s".format(x))
time.sleep(x)
if __name__ == '__main__':
t1 = time.time()
run()
cost_time = time.time() - t1
print("cost time:", cost_time)
运行结果:cost time: 4.748389959335327,其实并没有提高效率
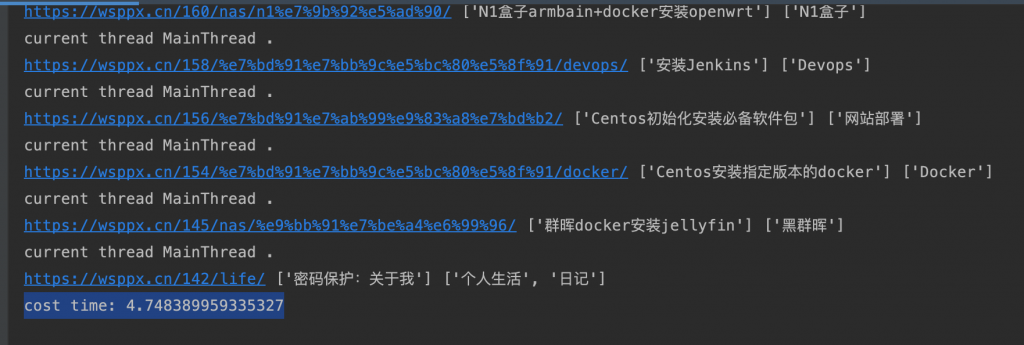

协程之python3.3中的yield from
yield from就我个人而言,在工作上基本上没有用过,因为后面的版本出现asyncio 替代它实现了异步协程,这东西很鸡肋
在功能上yield from items 类似 for item in items:return yield item,其实就是给你少写了一个循环,当然深究的话,yield from在处理异常方面也做了改进,又兴趣的同学可以看下源码
import time
def run():
astr = "ABC"
alist = [1, 2, 3]
adict = {"ip": "8.8.8.8", "addr": "google"}
agen = (i for i in range(50, 60))
def gen(*args, **kwargs):
for item in args:
yield from args
# 等价上面的yield from
# for item in args:
# for i in item:
# yield i
new_list = gen(astr, alist, adict, agen)
print(list(new_list))
if __name__ == '__main__':
t1 = time.time()
run()
cost_time = time.time() - t1
print("cost time:", cost_time)
协程之python3.6中的asyncio
- 协程函数: 定义形式为一定是
async def的函数; - 协程对象: 调用 协程函数 所返回的对象。
需要注意的是,创建一个协程又三种方法,asyncio.create_task / loop.create_task / asyncio.ensure_future,在python3.7之后其中asyncio.create_task就是用的loop.create_task
loop.create_task接受的参数需要是一个协程,但是asyncio.ensure_future除了接受协程,还可以是 Future 对象或者 awaitable 对象
import asyncio
import time
import requests
from lxml import etree
def request_web():
url = "https://wsppx.cn/date/2021/06/"
resp = requests.get(url)
text = resp.text
html = etree.HTML(text)
wsppx_urls = html.xpath("//h2[@class='item-title']/a/@href")
return wsppx_urls
async def request_artice(url):
print("start request url:",id(url),url)
resp = requests.get(url)
text = resp.text
html = etree.HTML(text)
wsppx_title = html.xpath("//h1[@class='entry-title']/text()")
info = html.xpath("//div[@class='entry-info']/a/text()")
# print(wsppx_title, info)
await asyncio.sleep(1)
print("end request",id(url))
return wsppx_title
async def run():
urls = request_web()
tasks = []
for url in urls:
task = asyncio.create_task(request_artice(url))
# task = asyncio.ensure_future(request_artice(url))
tasks.append(task)
return await asyncio.gather(*tasks, return_exceptions=True)
def wait(x):
print("wait sleep {}s".format(x))
time.sleep(x)
if __name__ == '__main__':
t1 = time.time()
# py3.7之前用这个
loop = asyncio.get_event_loop()
data = loop.run_until_complete(run())
# py3.7之后用下面的
# data = asyncio.run(run())
print(data)
cost_time = time.time() - t1
print("cost time:", cost_time)
协程yield、yield from、gevent、asyncio比较
其实没啥比较的,因为都是版本更新带来的必然结果
- 如果是用生成器的话yield、yield from,
- yield from iterable本质上等于for item in iterable: yield item的缩写版
- 如果是协程,python2用gevent,在python3.6之后就可以用asyncio
多线程
说到多线程一定会提到GIL(Global Interpreter Lock)锁,这个后面会专门有一节会讲到这个,GIL是一种粗粒度的全局锁,它的出现是为了解决多线程安全的问题,那什么又是线程安全呢?多线程环境经常出现抢占资源、死锁、数据同时存取的问题,那么为了解决这个问题,就需要给线程加锁,保证同一时刻只有一个线程对共享资源进行存取。GIL就是保证在单核cpu的情况下只有一个线程在调度。
那现在很多电脑都是多核的,11代的cpu都能达到8核心了。GIL在面对多核心的cpu劣势很明显了,不能充分利用多核cpu。那真的没有办法吗,其实不然,我们可以多进程+协程的方式也能做到高并发。
下面多线程爬虫例子
- 正常爬虫的写法
# -*- coding: utf-8 -*-
# @Time : 2021/7/27 1:43 下午
# @Author : wsppx
# @File : test_yield.py
# @Software: PyCharm
import time
import requests
from lxml import etree
def request_web():
url = "https://wsppx.cn/date/2021/06/"
resp = requests.get(url)
text = resp.text
html = etree.HTML(text)
wsppx_urls = html.xpath("//h2[@class='item-title']/a/@href")
return wsppx_urls
def request_artice(url):
resp = requests.get(url)
text = resp.text
html = etree.HTML(text)
wsppx_title = html.xpath("//h1[@class='entry-title']/text()")
info = html.xpath("//div[@class='entry-info']/a/text()")
print(url, wsppx_title, info)
def run():
urls = request_web()
for url in urls:
request_artice(url)
if __name__ == '__main__':
t1 = time.time()
run()
cost_time = time.time() - t1
print("cost time:", cost_time)
运行结果: cost time: 4.8902060985565186
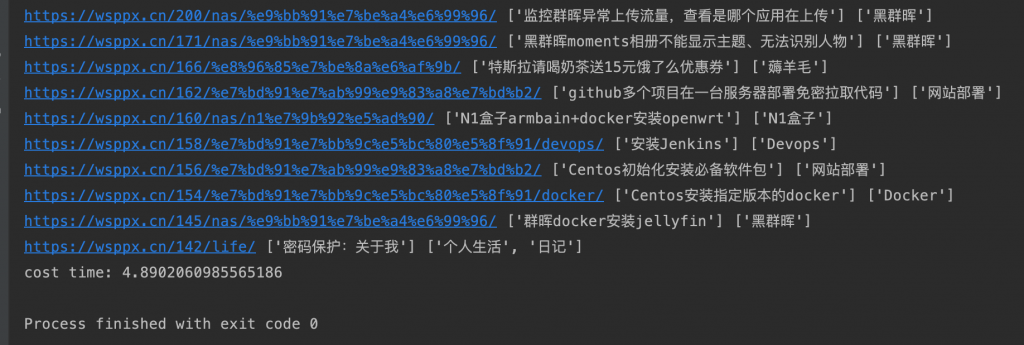
- 使用多线程
# -*- coding: utf-8 -*-
# @Time : 2021/7/27 1:43 下午
# @Author : wsppx
# @File : test_yield.py
# @Software: PyCharm
import time
import threading
import requests
from lxml import etree
def request_web():
url = "https://wsppx.cn/date/2021/06/"
resp = requests.get(url)
text = resp.text
html = etree.HTML(text)
wsppx_urls = html.xpath("//h2[@class='item-title']/a/@href")
return wsppx_urls
def request_artice(url):
resp = requests.get(url)
text = resp.text
html = etree.HTML(text)
wsppx_title = html.xpath("//h1[@class='entry-title']/text()")
info = html.xpath("//div[@class='entry-info']/a/text()")
print('current thread %s .' % threading.current_thread().name)
print(url, wsppx_title, info)
def run():
threads = []
urls = request_web()
for url in urls:
t = threading.Thread(target=request_artice, args=(url,))
threads.append(t)
for t in threads:
# t.setDaemon(True) # 守护线程,也就是把所有的子线程都变成主线程的守护线程,当主线程结束后,守护子线程也会随之结束,整个程序也跟着退出。
t.start()
t.join() # 将线程挂起,调用该方法将会使主调线程堵塞,直到被调用线程运行结束或超时,也就是主线程执行完毕之前,必须等待子线程执行结束
def wait(x):
print("wait sleep {}s".format(x))
time.sleep(x)
if __name__ == '__main__':
t1 = time.time()
run()
cost_time = time.time() - t1
print("cost time:", cost_time)
执行结果:cost time: 4.726883172988892,你是不是发现,并没有提高速度,执行多次,还会比单线程慢呢?

- 我们修改下main函数,在主线程增加一个睡眠函数
if __name__ == '__main__':
t1 = time.time()
run()
wait(6) # 睡眠6秒
cost_time = time.time() - t1
print("cost time:", cost_time)
运行结果:cost time: 6.569008111953735,你会发现
- wait(6)在run()之前执行了,这是因为线程是异步的,不需要等待线程执行完再执行下面一个函数。
- 总耗时才6.5,而不是6s+之前的4.6s呢?是因为当出现阻塞IO,cpu会切换线程,也就是先sleep 6s,这里就是阻塞IO,cpu会释放全剧锁GIL,其他的线程获取锁,继续执行,肉眼看是并发的感觉,其实只是线程切换。这也说明了,为啥上面执行用多线程,并没有加速,因为没有出现阻塞IO,效率并没有提升,而这里出现了一个6s的IO阻塞,就会切换线程执行,提高效率。
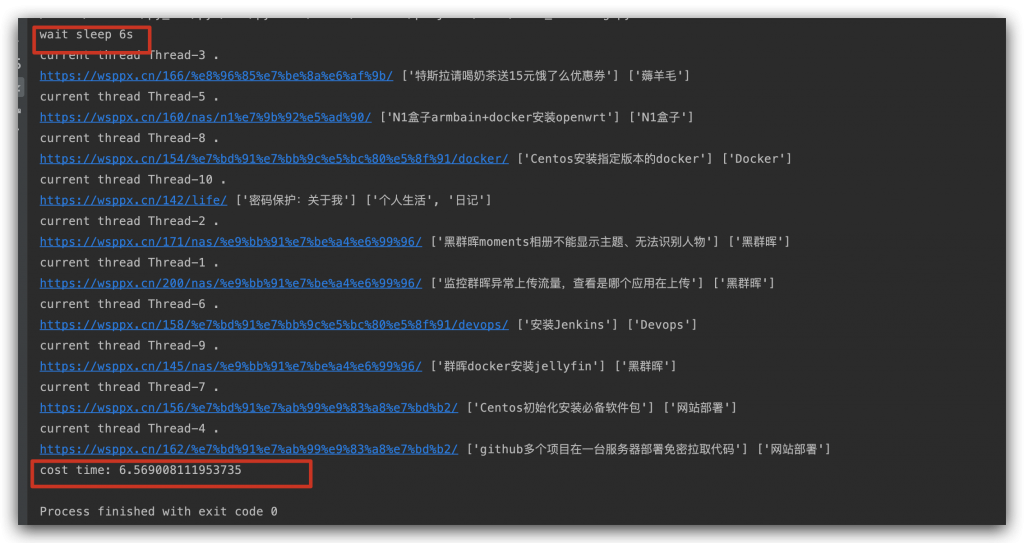
多线程互斥锁
上面的多线程并没有出现共享变量被同时存取的问题,如果出现共享变量,多个线程同时修改的话,会导致数据错误,因为我们需要线程安全,必须加锁
不加锁的例子,结果counter是随机的,不是0
# -*- coding: utf-8 -*-
# @Time : 2021/7/27 1:43 下午
# @Author : rickzuo
# @File : test_yield.py
# @Software: PyCharm
import time
import threading
s_time = time.time()
counter = 0
def add():
global counter
for _ in range(1000000):
counter = counter + 1
def sub():
global counter
for _ in range(1000000):
counter = counter - 1
threads = []
t1 = threading.Thread(target=add)
t2 = threading.Thread(target=sub)
t1.start()
t2.start()
t1.join()
t2.join()
print("counter:",counter)
cost_time = time.time() - s_time
print("cost time:", cost_time)
加锁之后counter结果为0
import time
import threading
lock = threading.Lock()
s_time = time.time()
counter = 0
def add():
global counter
lock.acquire()
for _ in range(1000000):
counter = counter + 1
lock.release()
def sub():
global counter
with lock:
for _ in range(1000000):
counter = counter - 1
if __name__ == '__main__':
t1 = threading.Thread(target=add)
t2 = threading.Thread(target=sub)
t1.start()
t2.start()
t1.join()
t2.join()
print("counter:", counter)
cost_time = time.time() - s_time
print("cost time:", cost_time)
多线程死锁
多进程
其实,从上面来看,多线程并没有想的那么快,那我们能不能加速呢?答案是可以的,我们可以用多进程,重复利用多核cpu执行。
还是以上面的例子,修改下run函数
# -*- coding: utf-8 -*-
# @Time : 2021/7/27 1:43 下午
# @Author : wsppx
# @File : test_yield.py
# @Software: PyCharm
import time
import threading
from multiprocessing import Pool
from os import cpu_count
import requests
from lxml import etree
def request_web():
url = "https://wsppx.cn/date/2021/06/"
resp = requests.get(url)
text = resp.text
html = etree.HTML(text)
wsppx_urls = html.xpath("//h2[@class='item-title']/a/@href")
return wsppx_urls
def request_artice(url):
resp = requests.get(url)
text = resp.text
html = etree.HTML(text)
wsppx_title = html.xpath("//h1[@class='entry-title']/text()")
info = html.xpath("//div[@class='entry-info']/a/text()")
print('current thread %s .' % threading.current_thread().name)
print(url, wsppx_title, info)
def run():
urls = request_web()
process_pool = Pool(processes=cpu_count())
for url in urls:
process_pool.apply_async(request_artice, (url,))
process_pool.close()
process_pool.join()
def wait(x):
print("wait sleep {}s".format(x))
time.sleep(x)
if __name__ == '__main__':
t1 = time.time()
run()
cost_time = time.time() - t1
print("cost time:", cost_time)
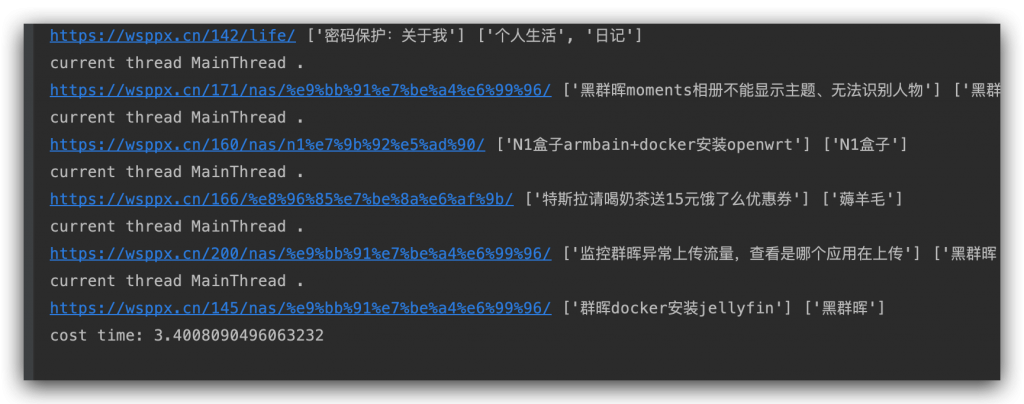
运行结果:cost time: 3.400,是不是快了很多
原创文章,作者:站长,如若转载,请注明出处:https://wsppx.cn/644/%e7%bd%91%e7%bb%9c%e5%bc%80%e5%8f%91/
 微信扫一扫
微信扫一扫
相关推荐
-
golang同目录调用其他文件函数的用法
问题复现 解决方法 这个应该是新手常见的问题,golang的包管理方式,这个运行错误是由于你执行了main.go,而没有编译其他go文件,当然不知道run函数哪里来的 正确方式 g…
-
记一次Proto Http请求报错问题:unKnow error: proto: (line 1:9): invalid value for int32 type: 100100013100
背景 kratos支持rpc和http方式进行通信,由于不同集群,不能进行内网通信,最终还是用http的方式,由于部门用的都是kratos,因此可以不用修改原来的通信方式,只是将之…
-
grpc请求超时处理
错误描述 grpc默认超时时间是1s,有些框架是500ms,当超时了会报如下错误: 客户端 client连接 controller 服务端增加超时 controller
-
前端学习记录之一:函数式编程
本节回顾 1.函数式编程(核心思想:把运算过程抽象成函数) 2.函数相关复习(函数是一等公民,高级函数,闭包) 3.函数式编程基础(lodash,纯函数,柯里化,管道,函数组合) …
-
http/https协议面试题
如何你的简历上写了熟悉http协议的,那就要准备这个面试了 http是长连接吗? 在http1.0的时候是短连接,每次与服务端通信都需要建立新的连接,也就是三次握手 在http1….